
When Guido Van Rossum was designing Python in 1989, we are pretty sure he never thought it would deliver so many applications in the future. Python’s object-oriented approach that helps programmers from all over the globe to write clear and logical code is one of the biggest reasons behind it. If you are not from the technical field, you will definitely be awestruck while Googling applications that Python offers in today’s market. It’s playing an impressive part in almost every technical advancements that we are experiencing at the moment. Python has surely become a pioneer for businesses to achieve better results in today’s date. Python web scraping is very important in web development.
It is exceptional in web development, game development, data science and visualization, and many different areas. But being the third most popular language, Python is also diligent in “Web Scraping,” which makes your life easier if your job requires pulling a large amount of data from the internet.
What is Web Scraping?

Web Scraping is an automated algorithm used to extract large amounts of data from the web in simple language. Now you might be thinking, why is it difficult to extract the data from the websites? All this available Data is unstructured, and that’s what makes web scraping useful as it helps collect this unstructured data from these websites and store it in a structured form. Whether you are an engineer, programmer, or data scientist, if your work includes analyzing large amounts of datasets of the internet, then the ability to use web scraping through Python would be a really useful skill to have at the moment.
How Can Web Scraping Be Used for Greater Good?

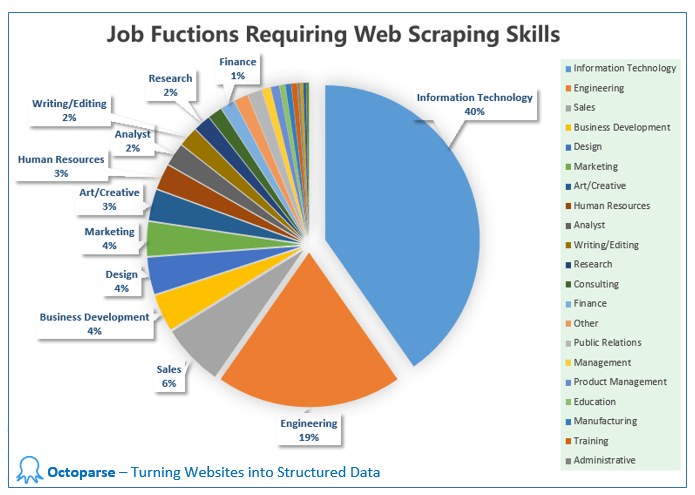
If you have never heard about web scraping, you might be wondering how it can be helpful to you or maybe your business. To find the answer to this question, you need to look at it from a different angle. If we can answer what kind of data a web scraping code can collect, you will automatically comprehend where you can use the stats you got from this method. Let us simplify this for you by mentioning a few Web Scraping applications and how the collected data can be used to offer better services.
- Email Address – If you have never leveraged the benefit of email marketing, you are missing out on the long term. Nevertheless, many desired companies use email as a great marketing prospect, and for that, they need to collect email ids, and web scraping can help them get this Data in an organized way so it can be used to send bulk emails.
- Social Media Scraping – Social Media has emerged as a boon for business only if you know the methods to help your business grow. One way is to use web scraping to collect data like trending events, customer preference, etc., from social media websites and use them for better sales.
- Research and Development – Research and Development are among the first few steps for an emerging organization. The success of research and development lays a foundation for the further growth of the company. With web scraping, you can collect large data sets and analyze them to get a better idea in which direction you are moving.
With data, the possibility is endless. And that is why learning web scraping data from the internet is one of the ascending skills to have at present. But since we are collecting data and that too possibly without telling the primary sites, a question arises in our curious minds. If you do not know what we are talking about, hop onto our next blog section.
Is Web Scraping Legal?
Well, everything indeed has a dark side in this world. When it comes to web scraping, legal and illegal issues depend on the websites, whether they allow data scraping or not. Before you start web scraping on a particular site, you should append the website’s robots.txt file. It will give you all the website details, including whether it allows data scraping or will sue you if you try to get data from their site.
However, web scraping is definitely illegal when trying to get non-public or confidential data out of somewhere. There is a reason why it’s a private file, and if you try to wrest such data, then it’s undoubtedly a clear violation of the legal terms.
Basics of Web Scraping
Web Scraping Consists of two parts: a web crawler and a web scraper. These two are like Sherlock Holmes and Dr. Watson. Well, the crawler leads the scrapper so that it can collect the requested data. We are leaving the mystery for you to decide who is Sherlock and who is Dr. Watson. Decide quickly because we need to understand what these two components do in web scraping.
- The Crawler – A web crawler is also known as a “Spider,” which is generally like a crawler in search engines that indexes the websites for the relevant content and showcases it on SERPs. However, in this context, it’s an artificial intelligence technology that searches for the content provided by the links. It searches for the relevant information asked by an algorithm that you create. But instead of showcasing it on SERPs, it brings the data to you.
- The Scrapper – A web scraper is a useful tool designed to extract data from several websites instantly and effectively. Web Scrapers vary widely in design and complexity, depending upon the requirement of the project.
How to Scrape data from a website?
The basic web scraping method includes running the developed code for web scraping, which sends a request to the URL from which you need to extract data. In response to your request, the server of that website sends you the Data that allows you to read the HTML or XML page. Once the data scraping is completed, your code parses the HTML or XML page to find the Data it brought with itself and extract it. Moreover, to extract data using web scraping with Python, you had to follow these basic steps:
- Finding the URL that you want to Scrape – It’s quite important to understand the requirements of your project at the early stages. Because the internet consists of millions of websites, finding the useful one at the early stages would be a peach for you.
- Inspecting the Page – The Data is extracted in raw HTML format, which means you need to be careful while parsing it and reducing the noise from the raw data.
- Find the Data you Want to Extract – A website contains a large amount of irrelevant information among the Data you want to extract, so use your precious time in scraping the data that will be helpful to you.
- Run the Code and Extract the Data – Once you have written the code to extract the information, run the code to extract the data and save it into CSV, XML, JSON file format.
Libraries Used for Web Scraping
Python offers a variety of libraries that we can use to scrape the web. We are pretty sure that we are going to see more libraries in the future because of the popularity of Python among programmers. In this section, let us talk about the current top 5 libraries used for web scraping using Python.
- Selenium –

Selenium is an open-source web-based tool you can use to open a web page, click on a button, and get results. It is one of the robust tools for web scraping, which was written in Java to automate tests. The best part of using Selenium is its user-friendly interface which makes it easy to learn and function. It also makes your code imitate human behavior, which is a must in automated testing. - Pandas –

Panda is usually used for thorough analysis and data manipulation in web scraping using Python. It helps you scrap the data and store it in the format you want it to. - BeautifulSoup –

BeautifulSoup is another extensive Python library used to extract information from XML and HTML files. If we ignore its name, Beautiful Soup is still a powerful tool because of its proficiency in detecting page decoding and getting more relevant data from the HTML text. Another plus point of Beautiful Soup is the simplicity and ease it offers while using it. - Scrapy –

Scrapy is another very popular web scraping library that you can use to systematically scrape and crawl around the internet. Apart from its main purpose of crawling the web on its own, it can also be used to monitor and mine data along with automated and systematic testing. - Urllib –

Urllib is a Python library that permits the developers to parse the info from HTTP protocols with ease.
Web Scraping with Python Best Practices and Tips
It is not that difficult to learn web scraping using Python. But if you want to increase your efficiency in the field, you need to undergo web scraping using best practices with some additional features.
- Check out if an API is available or not. There can be different possible scenarios even if API is available, so you need to consider all the possible cases and act accordingly.
- While making a request, the target website has to use server resources to respond. Scrapping during off-peak hours can offer quick results, especially when server load will be minimal compared to peak hours.
- Unlike humans, bots are pretty fast in what they do, but they are also predictable as a computer program. However, there are many anti-scraping technologies that websites use to block every kind of web scraping. But because of its predictable nature, you can confuse the anti-scraping technology by using some random actions. So, we suggest never following the same crawling pattern.
- Creating a monitoring process is another ingenious method to incorporate. Since data on many websites is time-sensitive, creating a long-lasting look that keeps on checking such URLs for scrape data at a certain set of intervals can get you new Data every time.
- Using Python request libraries is another strapping way as it makes sure to optimize HTTP methods before sending them to servers.
- Violating copyright terms on the data by extracting private Data is considered a serious issue in the industry. Most of the copyrighted data on the web are articles, stories, music, database, videos, pictures, etc. So, before you run your scraping code on a website, make sure you are not breaking the law, as Data needs to be legally scraped without infringing on the owner’s copyright.
Tips to Avoid Getting Blocked From Websites While Scraping
Data scraping not only requires your full attention because you are one step away from violation of the law, it also requires your complete responsibility. Many websites do not use any anti-scraping mechanism, but some block scrapers on their site, especially those who do not believe in sharing their data. Until you follow the scraping policies, you are good to go. Here are some tips to follow before you start scraping any new website.
- As mentioned, the speed of crawling done on websites by humans and bots is very different. Since bots are much quicker to scrape websites than us, making fast and random requests to a website will not do any good to you. It may even make your target website go down because of overloading requests. To avoid this mistake, we suggest you keep scraping slower; you can also make your bot sleep in between scraping at random intervals for this to not happen.
- The web scraping bots are just the programs as they will keep on following the same pattern as they are programmed. If you want to extract data from a particular website and do not want your bot to get banned permanently, then change your scraping pattern from time to time and detect every kind of website change.
- Honeypot Traps are the invisible links to detect web scraping or hacking on websites. If the owner doesn’t consider scraping data legal, they will consider web scraping as a hacking method. Because of this reason, many websites install honeypots that are invisible to normal users but can be seen by bots. So, you need to perform a honeypot check on each page before you start scraping. You need to find out if the link has the “display: none” or “visibility: hidden” CSS properties set.
Conclusion
Web Scraping is surely a technology that will see lots of advancements in the future, and since it is done using Python, we can expect something big from the community in the upcoming days.
We hope you found this blog detailed and informative and has added more knowledge about web scraping in your minds. Share your kudos and let our team know!